はじめに:「とりあえずやっといて」が失敗する構造的な原因
Claude CodeやCoworkといったAIエージェントツールを導入したものの、「思ったようなアウトプットが出てこない」「フォーマットを守ってくれない」「情報が不正確で使い物にならない」──こうした声は、2026年の現在でも非常によく耳にします。
しかし、問題の多くはAIの性能にあるのではありません。依頼の仕方、つまり「人間側の仕事の渡し方」に根本的な課題があるケースがほとんどです。
考えてみてください。もしあなたが新しく入った部下に「これやっといて」とだけ伝えて、完璧な成果物が出てくることを期待するでしょうか。普通は、仕事の目的、完成イメージ、判断基準、使うべきデータソースなどを伝え、最初は小さな単位で確認しながら進めていくはずです。
AIエージェントとの協働もまったく同じです。本記事では、PDCAサイクルをAIエージェントとの業務に適用し、段階的にアウトプットの品質を高めていく具体的な手法を解説します。Claude CodeのCLAUDE.mdを「育てる」ことで、2回目以降の作業では指示なしで同等の品質を再現できる仕組みの作り方まで、実践的にお伝えします。
この記事で学べること:
- AIエージェントへの依頼で失敗する典型パターンとその回避法
- Plan → Do → Check → Act の各フェーズで具体的に何をすべきか
- CLAUDE.mdを「業務マニュアル」として育てるテクニック
- 1回の成功体験を再現可能な仕組みに変えるフォルダ設計
想定読者: Claude CodeやCoworkを使い始めたが、期待した成果が出ていない方。プログラミング経験は問いません。
背景:なぜ今「エージェント時代のPDCA」が重要なのか
AIエージェントの進化と「丸投げ」の誘惑
2025年以降、AIエージェントツールは急速に進化しました。Claude Codeはターミナルからファイル操作、Web検索、コード実行まで自律的に行えるようになり、Coworkはデスクトップ環境でナレッジワーク全般を担えるツールへと成長しています。
この「なんでもできそう感」が、逆に落とし穴になっています。ツールが賢くなればなるほど、「とりあえず投げれば何とかしてくれるだろう」という期待が膨らむのです。
しかし現実には、AIエージェントが自律的に動けるのは**「何をすべきか」が明確に定義されている範囲内**に限られます。曖昧な指示に対しては、AIなりに「こうかな?」と推測して動きますが、その推測があなたの意図と一致する保証はどこにもありません。
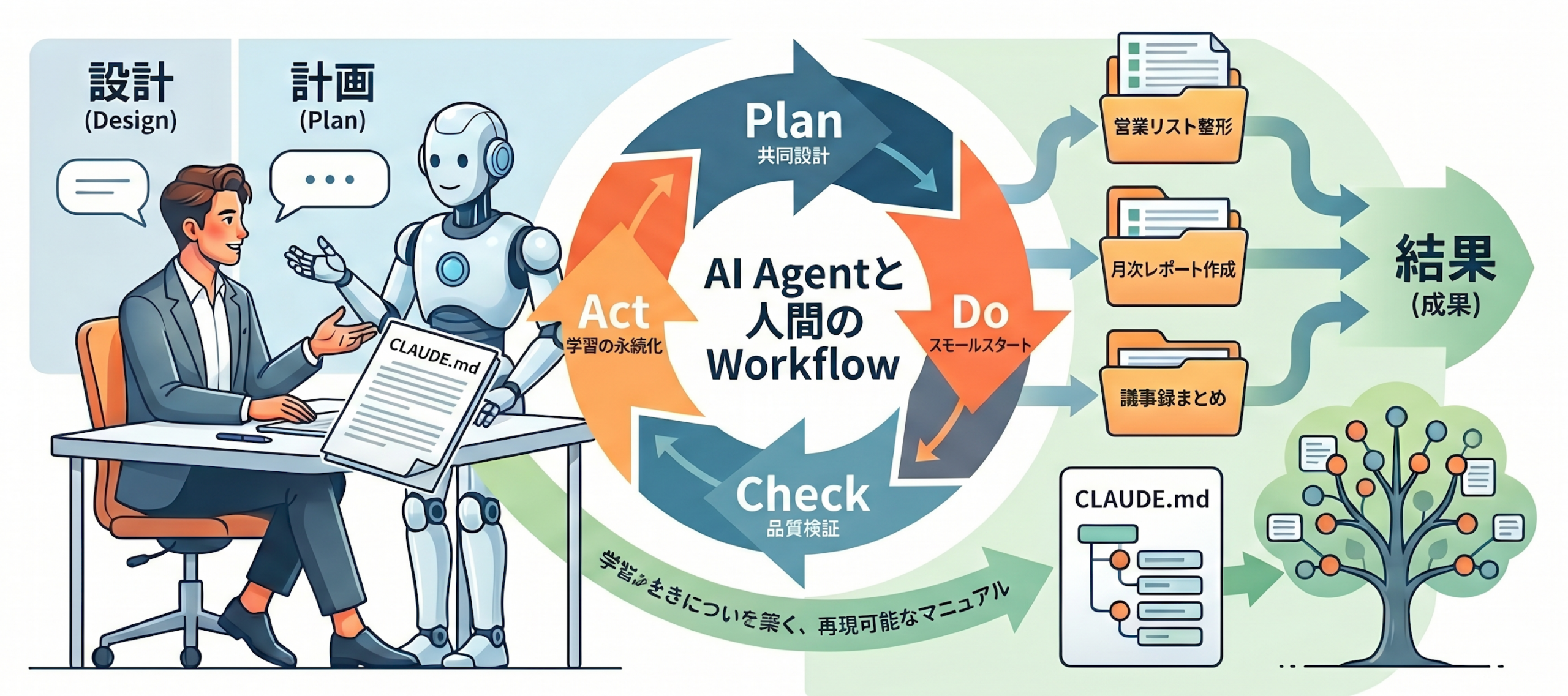
PDCAサイクルとは何か──AIエージェント文脈での再定義
PDCA(Plan-Do-Check-Act)サイクルは、製造業の品質管理から生まれたフレームワークです。これ自体は何十年も前からある「当たり前」の手法ですが、AIエージェントとの協働においては、各フェーズの意味合いが少し変わってきます。
| フェーズ | 従来のPDCA | エージェント時代のPDCA |
|---|---|---|
| Plan | 自分で計画を立てる | AIと一緒に計画を設計する |
| Do | 自分で実行する | AIに小規模で実行させる |
| Check | 結果を自分で確認する | AIの出力を人間が検証する |
| Act | 改善策を考えて実施する | フィードバックをCLAUDE.mdに蓄積する |
ポイントは、Planの段階からAIを巻き込むことと、Actの段階でCLAUDE.mdという永続的な記録に落とし込むことです。この2つが従来のPDCAとの決定的な違いになります。
準備:フォルダ設計とCLAUDE.mdの基本
業務単位でフォルダを分ける
Claude Codeでは、作業ディレクトリ(フォルダ)の単位でコンテキストが管理されます。これを利用して、1つの業務=1つのフォルダという設計にするのがおすすめです。
# 業務ごとにフォルダを作成
mkdir ~/work/営業リスト整形
mkdir ~/work/月次レポート作成
mkdir ~/work/議事録まとめ
こうすることで、各フォルダ内のCLAUDE.mdがその業務専用の「マニュアル」として機能します。営業リスト整形のフォルダで蓄積したノウハウが、議事録まとめの作業に混ざり込むことがなくなります。
CLAUDE.mdとは何か
CLAUDE.md(Markdown形式のテキストファイル)は、フォルダのルートに配置しておくと、Claude Codeがそのフォルダで作業を開始するたびに自動的に読み込む指示書です。
他のAIツールでいうと、ChatGPTの「GPTs」やDevinの「Playbook」に近い概念ですが、CLAUDE.mdの特徴はシンプルなテキストファイルである点です。特別なフォーマットや管理画面は不要で、普通のMarkdownファイルとして編集できます。
# CLAUDE.md の基本構造(例)
## このフォルダの目的
営業リストのビフォーデータを、定められたフォーマットに整形・拡充する
## 入力データ
- ファイル名: input.xlsx
- シート名: ビフォー
- 含まれる列: 企業名、業種、住所、電話番号、担当者名
## 出力フォーマット
- シート名: アフター
- 列構成: 企業名(正式名称)、業種(統一分類)、本社住所、電話番号、
担当者名、従業員数、直近売上、事業概要、自社との相性、相性の理由
## 処理ルール
- 企業名は正式名称に統一する(例: サイボウズ → サイボウズ株式会社)
- 住所は都道府県から番地まで記載する
- 不明な情報は「(不明)」と記載する
- 従業員数・売上は公式サイトから取得する
ただし、最初からこのような完成度の高いCLAUDE.mdを書く必要はありません。PDCAサイクルを回す過程で、徐々に内容を充実させていくのがこの手法の核心です。
Phase 1: Plan ── AIと一緒に設計する
「いきなり依頼」ではなく「まず相談」
PDCAサイクルの最初のフェーズであるPlan(計画)は、全体の成否を左右する最も重要なステップです。ここでの鉄則は、いきなり作業を依頼するのではなく、まず「どう進めるか」をAIに相談することです。
具体的には、以下のような形でClaude Codeに話しかけます。
このフォルダ内にあるExcelデータに対して、
ビフォーシートの内容をアフターシートに拡充しながら
データを整形していきたいと考えています。
どんな流れで進めるのがいいか、
また足りない情報はどう集めるか、
設計を一緒に考えてください。
これだけです。雑な指示に見えるかもしれませんが、ここで重要なのは**「やって」ではなく「一緒に考えて」と伝えている**点です。
AIが返してくる「確認事項」を活用する
上記のような相談をすると、Claude Codeは作業に取りかかる前に確認事項を投げ返してくれます。たとえば以下のような質問です。
- 「自社との相性」とは具体的にどの会社との相性ですか?会社のWebサイトを教えてもらえますか?
- 情報源は公式サイトがメインですか?それ以外のデータベースも使ってよいですか?
- 確認が取れない情報は空欄にしますか?それとも「不明」と記載しますか?
- 上場・未上場の区別は必要ですか?
こうした質問への回答を通じて、あなた自身も「何を求めているのか」を言語化できます。そしてAIはその回答をもとに、判定軸やスキーマの定義を提案してくれます。
Planフェーズで自分が考える必要はない
ここで強調しておきたいのは、このPlan自体を自分で一から書く必要はないということです。
チャットAI時代には「良いプロンプトを書けるかどうか」が成果を左右すると言われていました。しかしエージェント時代では、AIにデータを渡して「どう進めるか一緒に考えて」と相談すれば、AI自身が適切な設計を提案してくれます。
あなたの役割は、AIが出してきた設計案に対して「これでいい」「ここは違う」とフィードバックすることです。設計書を書くスキルがなくても、出てきたものに対して「合ってるかどうか」を判断するスキルがあれば十分です。
Plan完了時のチェックポイント
Planフェーズが完了した段階で、以下の項目が明確になっているか確認しましょう。
- 入力データの構造が把握できているか
- 出力フォーマット(列構成、データ型、粒度)が定義されているか
- 情報の取得先と優先順位が決まっているか
- 判断基準(相性判定の軸や閾値など)が言語化されているか
- 不明・欠損データの扱い方が決まっているか
これらが曖昧なまま次のフェーズに進むと、後からの手戻りが大きくなります。逆に言えば、ここさえしっかりしていれば、後のフェーズは比較的スムーズに進みます。
Phase 2: Do ── 小さく実行する
「全件処理」は最大のアンチパターン
Planが固まったら、次は実行フェーズです。ここでの最大の注意点は、いきなり全件を処理させないことです。
たとえば100件の企業リストがあったとして、いきなり「全部やって」と依頼するのは危険です。もし1件目の時点で判定基準のズレやフォーマットの不備があったとしたら、残り99件もすべて同じ問題を抱えた状態で完了してしまいます。やり直しの手間は計り知れません。
代わりに、こう伝えます。
まずは1件だけ処理してみてください。
結果を確認してから次に進みます。
1件目の処理結果を観察する
AIが1件目を処理すると、たとえば以下のような出力が得られます。
企業名: サイボウズ株式会社
業種: 情報・通信業
本社住所: 東京都中央区日本橋二丁目7番1号
電話番号: 03-XXXX-XXXX
担当者名: 山田太郎
従業員数: 約1,300名
直近売上: 約250億円
事業概要: グループウェア「kintone」「Garoon」等を提供する
SaaS企業。チームワークの向上を掲げ...
自社との相性: ◎
相性の理由: ① ホワイトカラー比率が高い(IT企業のため)
② DX導入への素地がある(自社がSaaS企業)
③ 規模感が適切(従業員1,000名超)
この段階で見るべきポイントは、大きく3つです。
1つ目はデータの正確性です。従業員数や売上の数値が実際と合っているか、公式サイトの情報と照合します。AIは「もっともらしい数値」を生成することがあるため、最初の数件は特に注意して確認する必要があります。
2つ目はフォーマットの適切さです。事業概要の文章の長さや粒度は期待通りか、相性の判定は軸に沿って行われているか、表記ゆれはないかを確認します。
3つ目は漏れている観点がないかです。実際の出力を見ることで、「URLも欲しいな」「AI活用状況の列も追加したいな」といった、計画段階では思いつかなかったニーズが浮かび上がることがあります。
2件目で再現性を確認する
1件目の結果がおおむね問題なければ、もう1件処理してもらいます。この2件目の目的は再現性の確認です。
1件目がたまたまうまくいっただけでないか、異なる業種・規模の企業でも同じ品質で処理できるかを確認します。ここで品質にバラつきがあれば、判定基準の定義が曖昧な証拠です。Planフェーズに戻って基準を明確化する必要があります。
Phase 3: Check ── 人間が品質を検証する
確認すべき4つの観点
Do(実行)フェーズの出力に対して、人間が確認すべき観点は大きく4つに分類できます。
① 事実の正確性 AIが記載した数値や事実が正しいかどうかです。従業員数、売上高、本社所在地などは公式サイトや有価証券報告書で裏取りできます。特に数値情報はAIが「それっぽい数字」を生成するリスクがあるため、最初の数件は必ず確認しましょう。
② フォーマットの一貫性 複数件を処理した場合、件ごとにフォーマットがブレていないかを確認します。たとえば、A社では事業概要が3行なのにB社では10行になっている、住所の表記が「東京都」と「東京」で揺れている、といった不整合がないかをチェックします。
③ 判定ロジックの妥当性 「自社との相性」のような定性的な判定がある場合、その判定結果とその理由が論理的に整合しているかを確認します。たとえば、研修事業を展開している会社が相性を判定する場合、「コンサルティングやアドバイザリーも含めた総合的な判定になっているか」といった観点です。
④ 抜け漏れの発見 実際に出力を見て初めて気づく「あったほうがいい列」や「もっと詳しく知りたい情報」を洗い出します。これは計画段階では見えなかった改善点であり、PDCAサイクルを回す最大のメリットです。
Checkフェーズの心構え
このフェーズで重要なのは、「ダメ出し」ではなく「改善点の発見」というマインドセットです。
AIの出力に対して「なんでこんなこともできないの」と思うのは簡単ですが、それではPDCAは回りません。「ここはいい、ここはこう直してほしい」と具体的なフィードバックを言語化することで、次のActフェーズでの改善が効果的になります。
Phase 4: Act ── 改善をCLAUDE.mdに蓄積する
フィードバックの2つの方向性
Checkフェーズで発見した改善点は、大きく2つの方向性で対処します。
方向性①:その場で修正して再実行する
たとえば「相性判定の基準に、コンサルティングやアドバイザリー支援も含めてほしい」という改善点が見つかった場合、Claude Codeに以下のように伝えます。
判定結果を見直してほしい。
研修だけではなく、コンサルティングやアドバイザリー支援も
含めた形で相性を判定してください。
この基準で再度実行してください。
方向性②:効率化のヒントをAIに聞く
1サイクルを回した後で、AIに振り返りを促すのも効果的です。
今回の実行を振り返って、
もっと効率的に処理する方法があれば教えてください。
無駄な処理やエラーの原因になりそうな部分があれば、
改善策も含めて提案してください。
AIは自分の処理過程を振り返り、「企業ごとにWeb検索するのではなく、先にまとめて情報を収集してからマッピングしたほうが速い」「サブエージェントを使って並列で調査すると効率が上がる」といった改善提案をしてくれます。
CLAUDE.mdに「学び」を書き込む
ここがPDCAサイクルの最重要ステップです。上記のフィードバックと改善を、CLAUDE.mdに反映してもらいます。
今回の内容をCLAUDE.mdにまとめてください。
次回同じ作業をする際に、
このファイルだけで同じ品質の作業ができるようにしてください。
Claude Codeはこの依頼に対して、今回のセッションで決まったこと(列の定義、判定基準、処理手順、効率化のコツなど)をCLAUDE.mdにまとめてくれます。
こうして完成したCLAUDE.mdは、次のセッションで自動的に読み込まれます。つまり、新しいセッションを開いた瞬間から、前回のセッションで蓄積した知識がすべて反映された状態で作業を開始できるのです。
CLAUDE.mdが解決する「引き継ぎ問題」
CLAUDE.mdがなぜ重要かを、もう少し掘り下げて説明します。
Claude Codeのセッション(チャット)は、長くなるとコンテキストウィンドウの上限に達して新しいセッションに移行する必要が出てきます。また、翌日に同じ作業をしたい場合も新しいセッションを開くことになるでしょう。
ここで問題になるのが、セッションをまたぐと、前のセッションでの会話内容をAIは覚えていないという点です。せっかく何十分もかけて判定基準をすり合わせ、フォーマットを調整したのに、新しいセッションではまたゼロからやり直し──これでは非効率この上ありません。
CLAUDE.mdは、この「引き継ぎ問題」を解決します。セッション内の一時的な記憶ではなく、ファイルとして永続化された指示書を読み込むことで、どのセッションでも同じ品質で作業を再現できるようになります。
人間の業務に例えるなら、属人的なノウハウを業務マニュアルに落とし込むのと同じです。担当者が変わっても(=セッションが変わっても)、マニュアルがあれば同じ品質の仕事ができるわけです。
実践テクニック:CLAUDE.mdを「育てる」コツ
コツ①:最初から完璧を目指さない
CLAUDE.mdは最初から完成版を書こうとするのではなく、PDCAを回しながら徐々に育てていくものです。
最初のバージョンは、フォルダの目的と入出力の概要だけで構いません。1サイクル回すごとに、判定基準の詳細、エッジケースの対処法、効率化のノウハウなどが追記されていきます。
# 初回のCLAUDE.md(最小限)
## 目的
営業リストの整形・拡充
## 入力
input.xlsx のビフォーシート
## 出力
同ファイルのアフターシート
↓ PDCAサイクルを3回回した後 ↓
# 3回目以降のCLAUDE.md(充実版)
## 目的
営業リストの整形・拡充
## 入力
input.xlsx のビフォーシート
- 列: 企業名、業種、住所、電話番号、担当者名
## 出力スキーマ
| 列番号 | 項目名 | 説明 | データソース |
|--------|--------|------|--------------|
| 1 | 企業名 | 正式名称(株式会社含む) | 公式サイト |
| 2 | 業種 | 総務省分類に準拠 | 公式サイト |
| 3 | 本社住所 | 都道府県〜番地 | 公式サイト |
| ... | ... | ... | ... |
| 10 | AI活用状況 | 生成AI・AIエージェントの導入状況 | ニュース記事・IR |
## 相性判定ルール
### 判定軸(各1-3点、合計6点以上で◎)
1. 業種・規模の親和性
2. ホワイトカラー比率
3. DX導入の素地
4. 競合状況
5. アプローチの容易性
### 注意事項
- 研修だけでなく、コンサルティング・アドバイザリーも含めて判定する
- IT企業だからといって自動的に◎にしない(競合SaaSとの関係も考慮)
## 効率化メモ
- 企業情報は1社ずつではなく、先にバッチで公式サイトURLを収集し、
その後まとめて情報取得するほうが速い
- サブエージェントを立ち上げて並列調査すると処理時間が半減する
コツ②:CLAUDE.mdが大きくなったら分割する
CLAUDE.mdはセッション開始時に毎回必ず全文が読み込まれます。そのため、ファイルが大きくなりすぎると、コンテキストウィンドウの容量を無駄に消費してしまいます。
目安として、CLAUDE.md本体は基本方針と処理フローの概要に留め、詳細な判定基準や参照データは別ファイルに分離するのがベストプラクティスです。
📁 営業リスト整形/
├── CLAUDE.md ← 基本方針・処理フロー(常に読み込まれる)
├── criteria.md ← 相性判定の詳細基準(必要時のみ参照)
├── schema.md ← 出力スキーマの定義(必要時のみ参照)
├── input.xlsx ← 入力データ
└── output.xlsx ← 出力データ
CLAUDE.md内では、以下のように別ファイルへの参照を記載しておきます。
## 相性判定ルール
詳細な判定基準は `criteria.md` を参照すること。
処理開始時にこのファイルを読み込んでから判定を行う。
こうすることで、CLAUDE.md自体はコンパクトに保ちつつ、必要な情報にはいつでもアクセスできる構成になります。
コツ③:「失敗」もCLAUDE.mdに記録する
うまくいったことだけでなく、失敗パターンや注意点もCLAUDE.mdに記録すると、同じミスの再発を防げます。
## 既知の注意事項
- 従業員数を「連結」と「単体」で混同しやすい。
原則として単体の数値を使用し、連結の場合は「(連結)」と注記する
- 非上場企業の売上情報は取得できないことが多い。
その場合は「(非公開)」と記載し、推定値は入れない
- 企業名の前株・後株を間違えやすい。公式サイトの表記に従うこと
これは、人間のチームでも「過去トラ(過去のトラブル事例集)」として共有される知識と同じです。AIエージェントに対しても、同じように「ここは気をつけて」と伝えておくことで、精度が格段に向上します。
さらに先へ:PDCAサイクルの発展的な活用
スキル化:フォルダを超えて再利用する
CLAUDE.mdはフォルダ単位で機能しますが、同じノウハウを複数の業務で使いたい場合は、エージェントスキル(Agent Skills)として切り出すことも可能です。
ただし、スキル化するとアップデートの管理が少し面倒になります。実務的には、まずはフォルダ内のCLAUDE.mdとして育て、内容が安定してきた段階でスキル化を検討するという段階的なアプローチがおすすめです。
自動化の「横展開」パターン
1つの業務でPDCAサイクルを回して仕組みが完成したら、そのフォルダは「テンプレート」として機能します。
たとえば、営業リスト整形の仕組みが完成したとします。新しい営業リストが来たら、そのフォルダにExcelファイルを入れて「ビフォーの全件を処理して」と指示するだけで、CLAUDE.mdに書かれた基準に従って自動的に処理が走ります。
これは、毎月の経理処理やYouTube動画のアップロード作業など、定型的だが手間のかかる業務に特に威力を発揮します。一度仕組みを作れば、2回目以降はほぼ「丸投げ」が成立するのです。
ここで面白いのは、最初に「丸投げはダメ」と言いましたが、正しくPDCAを回して仕組みを作った後であれば、丸投げが最適解になるという点です。最初のセットアップに30分〜1時間をかけることで、その後何十時間もの作業が自動化されるわけです。
サブエージェントとの組み合わせ
Claude Codeにはサブエージェント機能があり、メインのセッションから複数の調査タスクを並列で実行させることができます。
たとえば、営業リスト10件を処理する場合、1件ずつ逐次処理するのではなく、サブエージェントに分担して同時に調査させることで、処理時間を大幅に短縮できます。
この場合も、CLAUDE.mdにサブエージェントの使い方やタスク分割のルールを記載しておくと、次回以降は自動的に最適な並列処理が行われるようになります。
Ctrl+P(サイドチャット)の活用
Claude Codeでは、Windowsの場合Ctrl+P(macOSではCmd+P)でサイドチャットを開くことができます。メインのセッションでAIが調査・処理を実行している間に、サイドチャットで別の質問や確認ができるため、待ち時間を有効活用できます。
たとえば、メインで企業リストの処理を走らせながら、サイドチャットで「この業界の最近のトレンドを調べて」「次に処理するリストの準備状況を確認して」といった使い方が可能です。
よくある失敗パターンと対策
PDCAサイクルを実践する中で陥りやすい失敗パターンとその対策を整理しておきます。
| 失敗パターン | 原因 | 対策 |
|---|---|---|
| Planを飛ばしていきなり全件処理させる | 「AIなら大丈夫だろう」という過信 | 必ず1-2件のテスト実行から始める |
| AIの出力をノーチェックで受け入れる | 確認が面倒・AIを信頼しすぎ | 最初の数件は必ず裏取りする |
| 改善点を口頭で伝えるだけで記録しない | CLAUDE.mdの重要性を認識していない | 改善のたびにCLAUDE.mdに反映する |
| CLAUDE.mdを一度も更新しない | 「最初に書いたから完成」と思い込む | 定期的に振り返りと更新を行う |
| CLAUDE.mdに何でも詰め込みすぎる | 「多いほど良い」という誤解 | 基本方針は簡潔に、詳細は別ファイルへ |
まとめ:4つのポイント
本記事で解説したエージェント時代のPDCAサイクルを、4つのポイントに凝縮します。
🔹 ポイント1:いきなり頼まず、まずは設計する 「とりあえずやって」ではなく「どう進めるか一緒に考えて」から始める。設計はAIと一緒に作るもので、自分一人で仕様書を書く必要はありません。
🔹 ポイント2:小さく実行して検証する 最初は1件、次に2件と段階的に処理し、人間が品質を確認してからスケールする。いきなり全件処理は最大のアンチパターンです。
🔹 ポイント3:CLAUDE.mdにノウハウを蓄積する セッション内の一時的な成功体験を、CLAUDE.mdという永続的なファイルに落とし込む。これにより、セッションをまたいでも同じ品質の作業が再現可能になります。
🔹 ポイント4:CLAUDE.mdは「育てる」もの 一度書いて終わりではなく、PDCAを回すたびにアップデートしていく。最初は最小限で始めて、徐々に精度と効率を上げていくのが現実的なアプローチです。
AIエージェントは、正しく使えば驚くほど高い精度で仕事を自動化できます。しかし、その「正しく使う」の本質は、高度なプロンプト技術ではなく、計画→小規模実行→確認→改善という、昔から変わらない仕事の基本を丁寧に回すことにあります。
今日からぜひ、あなたの業務でもPDCAサイクルを試してみてください。最初の1サイクルを回すのに30分もかかりませんが、その30分が、今後何十時間もの時間を生み出すきっかけになるはずです。
参考リソース
- Claude Code 公式ドキュメント ── Claude Codeの基本的な使い方と機能一覧
- CLAUDE.md のベストプラクティス ── CLAUDE.mdの書き方に関する公式ガイダンス
- PDCA Code Generation Process (GitHub) ── PDCAフレームワークをClaude Codeスキルとして実装したオープンソースプロジェクト
- https://www.youtube.com/watch?v=3S-lFrsttto

